

Exploring AWS !!
Day 41:
Amazon Aurora — Part 2
Aurora Replicas Autoscaling: scale the replicas based on the target value by adding or removing them. Best suitable for predictable workloads.
Aurora — Custom Endpoints
- Define a subset of Aurora Instance as a custom endpoint
- Example: Run analytical queries or specific replicas
- The reader endpoint is generally not used after defining custom endpoints.
Aurora Serverless:
- Automated database instantiation and autoscaling based on actual usage.
- Good for infrequent, intermittent or unpredictable workloads.
- No explicit planning needed.
- Pay per second, can be more cost effective.
Aurora Multi-Master:
- In case you want an immediate failover for write node (High Availability)
- Every node does Read/Write vs promoting a Read Replica as a new master.
Global Aurora:
- Aurora Cross Region Read Replicas:
Useful for disaster recovery
Simple to put in place
- Aurora Global Database (recommended):
1 Primary Region (read/write)
Upto 5 secondary (read only) regions, replication lag is less than 1 second.
Upto 16 read replicas per secondary region.
Helps for decreasing latency.
Promoting another region (for disaster recovery) has an RTO (Recovery Time Objective) of < 1 minute
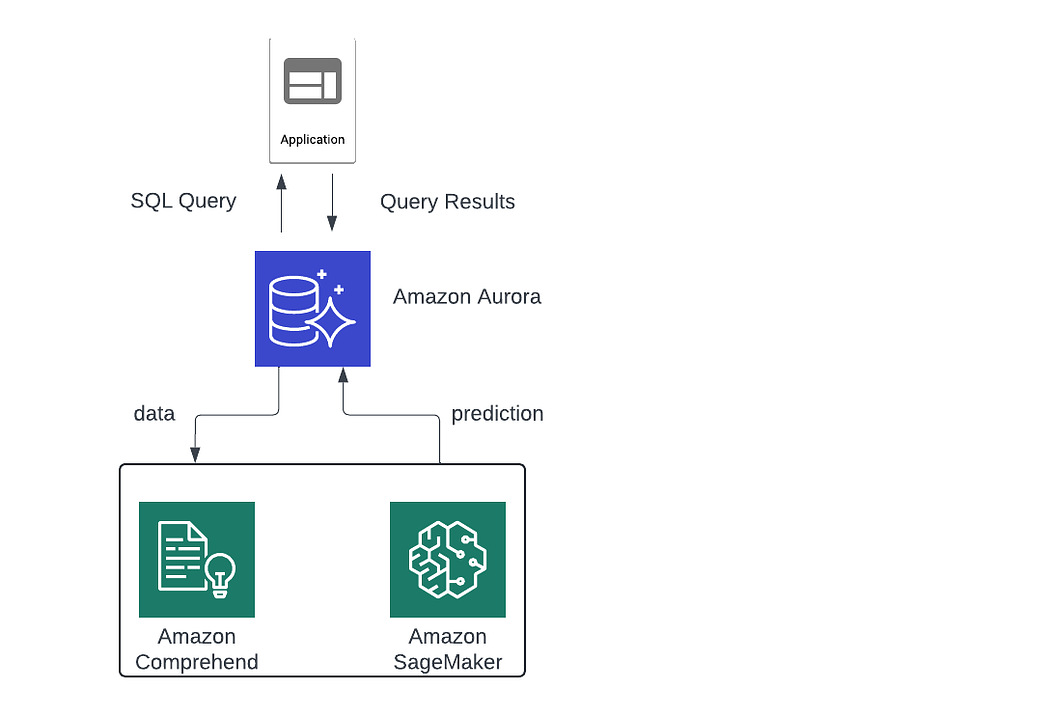
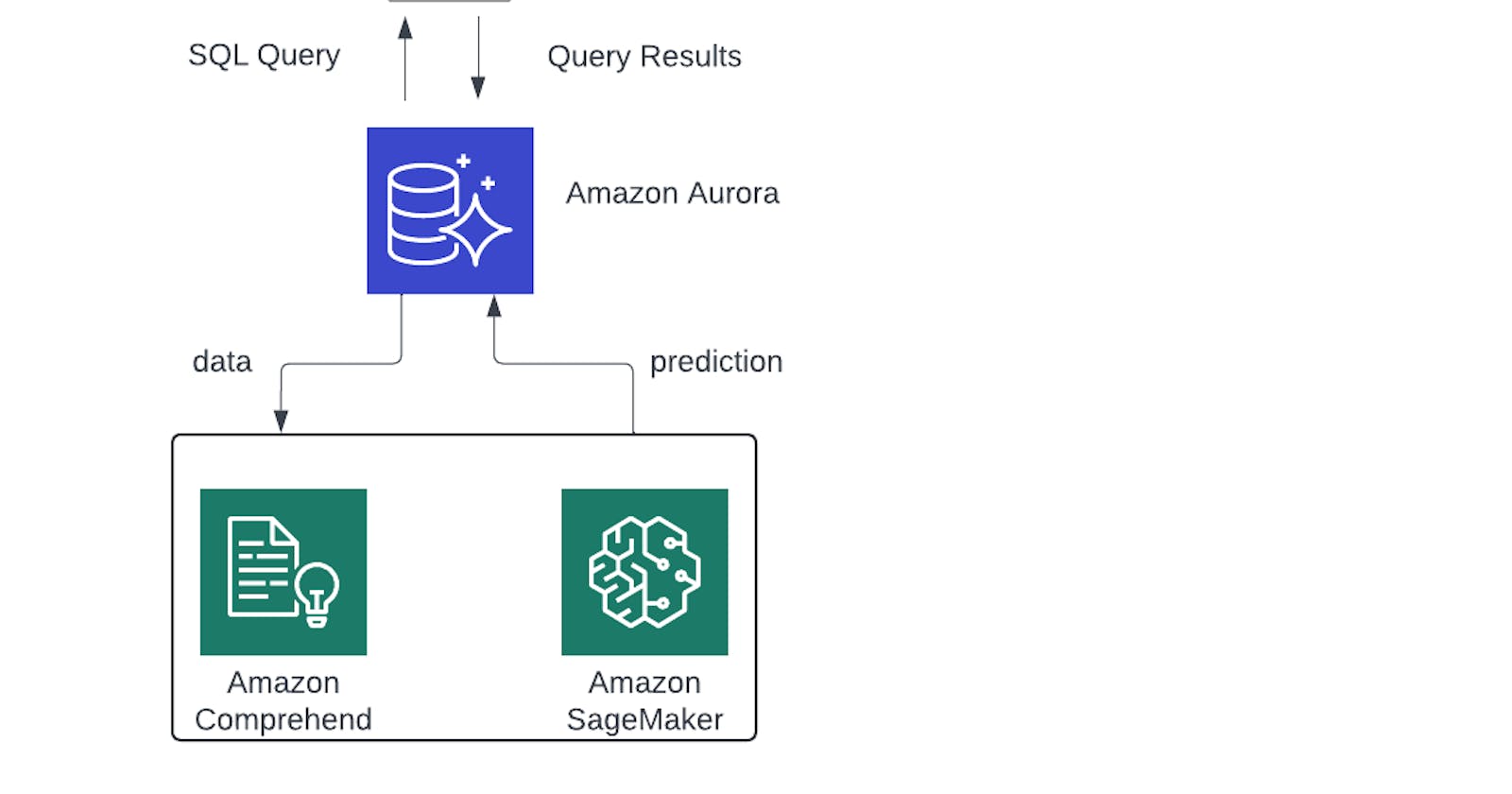
Aurora Machine Learning:
- Enables you to add Machine Learning based predication to your applications via SQL.
- Simple, optimized and secure integration between Aurora and AWS Machine Learning services.
- Supported services:
Amazon SageMaker (use with any ML model)
Amazon Comprehend (for sentimental analysis)
- Don’t need to have ML experience.
- Use Case: Fraud detection, ads targeting, sentiment analysis, product recommendation